




Microsoft Azure has lately seen substantial growth as more and more businesses choose to use it. Azure provides a variety of services across many different industries, such as database management, networking, content delivery, etc. The number of individuals searching for Azure Cosmos DB tutorials, how Cosmos DB operates, the introduction to Azure Cosmos DB, the basics of Cosmos DB, etc., has significantly increased. With the help of Azure’s tools and technologies, Cosmos DB on Azure offers an exclusive, globally spread out, multi-model database service with high efficiency, high availability, and low latencies.
To fully understand Cosmos DB, we must first understand relational, NoSQL, distributed, and multi-model databases.
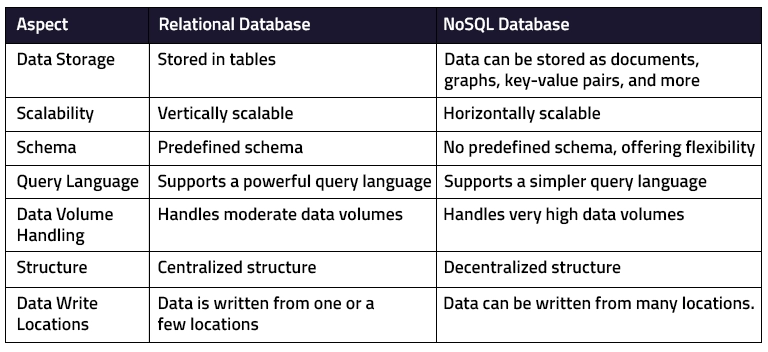
Relational database
A relational database is a type of database that stores data that is connected. Data in a relational model is stored as rows and columns in tables. The columns are used to hold certain types of information about several items, whereas the rows represent various aspects of one object. Primary keys may be used to uniquely identify rows, while foreign keys can be used to connect distinct tables.
NoSQL database
NoSQL databases are used for data that is not represented in the same manner that relational databases are. NoSQL supports data structures such as key-value pairs, broad columns, graphs, and documents that are not found in relational databases. This makes them more adaptable and allows for speedier operations.
Relational vs. NoSQL Database
Distributed database
A distributed database is one in which data in a database is kept in several physical places. The data can be kept on several computers in a single physical location or on multiple computers in separate networked places.
Data can be stored in several locations in two ways:
- Replication: Redundant copies of the database are kept in many locations. As a result, any changes made in one area must likewise be implemented in all other locations.
- Fragmentation: The database is divided into fragments that are kept in multiple locations.
Multi-Model database
Multi-model databases are database models that can handle both relational data models and NoSQL models.
Azure Cosmos DB
For handling data at a huge scale, Cosmos Database (DB) is a horizontally scalable, globally dispersed, fully controlled, low latency, multi-model, and multi-query-API database. A cloud-based NoSQL database, Cosmos DB is a PaaS (Platform as a Service) solution from Microsoft Azure. Cosmos DB is also known as a serverless database. All Azure regions provide Cosmos DB, which is a superset of Azure Document DB.
By replicating the data to the geolocation from which your users are accessing it, you may spread the data across any number of Azure regions using Cosmos DB, which aids in providing data to users rapidly and with little latency.
Features of Cosmos DB
- Globally distributed: Your data may be reproduced globally with Azure Cosmos DB by adding Azure regions with a single click.
- Linear scalability: The ability to manage growing demand by adding additional servers to the cluster is referred to as linear scalability. Cosmos DB can be horizontally scalable to accommodate hundreds of millions of read and write transactions per second.
- Schema-Independent indexing: Cosmos DB’s database engine is schema-agnostic, allowing for automated data indexing. Cosmos DB dynamically indexes all data, eliminating the need for schema and index administration.
- Multi-Model: Cosmos DB is a multi-model database, which means it can store data in Document-based, Key-value Pair, Graph-based, and Column Family-based databases. Global distribution, horizontal partitioning, provisioning throughput, and automated indexing capabilities are the same regardless of the model you pick for your data permanence.
- Support for several APIs and languages: Microsoft provides SDKs for a variety of programming languages, including Java, .NET, Python, Node.js, JavaScript, and others. Cosmos DB supports a variety of APIs, including SQL API, Cosmos DB Table API, MongoDB API, Graph API, Cassandra API, and Gremlin API.
- Support for multiple consistencies: Cosmos DB provides five degrees of consistency: Eventual, Prefix, Session, Bounded, and Strong.
- Indexes data automatically: Cosmos DB automatically indexes data on ALL fields in ALL documents by default, eliminating the need for secondary indexes, but you may still define custom indexes. The automated indexing capabilities of Azure indexes every property of every record without the need to specify schemas and indices in advance. This feature applies to all data models.
- High availability: For multi-region accounts with multi-region writings, Cosmos DB guarantees 99.999% availability for both reads and writes. For single-region accounts, Cosmos DB delivers 99.99% availability for both reads and writes. If there is a regional calamity, Cosmos DB will immediately fail. If this occurs, the app may also fail programmatically.
- Low Latency: For all consistency settings, Azure Cosmos DB offers 10 milliseconds latency at the 99th percentile for both writes and reads. Data may be geographically spread across any number of Azure regions, such that the stored data is available closest to the consumers, reducing the potential delay in getting the data.
- Support for Multiple Masters: Cosmos DB enables multi-master, which implies that writes, like reads, may be elastically scaled over any number of Azure locations across the world. You may configure all data servers to behave as write servers using the multi-master capability. You must allow multi-region writes for your apps to use the multi-master capability. To set up the multi-master functionality, follow these steps.

How does Azure Cosmos DB work?
The individuals who are close to the place have the advantage. They will be able to get the data faster than the rest of the globe owing to network latency concerns. That is if a website used by users from all over the world publishes its data into a primary database in one location (non-multi-master mode).
Suppose you have a website that gets visited by people from different regions and that the database writes are being sent to the US region’s database (in non-multi-master mode). This database is regarded as the main one. Due to network latency, users in the US will be able to access the data more quickly than users in other geolocations when it is written to the US database. The data is simultaneously written to all the chosen regions if the multi-master option is enabled.
The data must be duplicated to the user’s closest location for users to get the data more quickly from the closest region, which will address the latency concerns. For instance, a user needs to be able to access data from the Delhi area if they are based in Delhi, India. Create read databases close to where your users are located and duplicate the data there from the master database. When information is added to the main database, copies of that information are sent to widely dispersed read databases.
Cosmos DB has multi-master functionality, allowing data to be simultaneously written into several databases dispersed around the world. So that it may be accessed more quickly, the data is copied onto the user’s closest area. However, there may still be a millisecond gap between the data being repeated, which has an impact on consistency.
If the data are consistent, it means they are always in synchronization and the same condition.
When building Cosmos DB, we have the option to specify a default consistency that may be modified by the application when retrieving data.
Want to understand Azure’s foundational concepts? Learn about our Microsoft Azure training course and earn your certification.
Levels of Consistency in Cosmos DB
- Eventual: In this case, data is written on the primary node and finally transmitted to read-only subsidiary nodes. The user’s access to the most recent data may be delayed.
- Consistent: Viewers can read data in the same sequence as it is written if the prefix is consistent.
- Session: Users who have recently saved the data will be able to see it during this session, but it will take a while for the other users to view the latest version of the data.
- Bounded Staleness: A staleness time that prevents data from being replicated to secondary nodes can be specified here.
- Strong: Despite having a low performance, this provides all users with the most recent copy of the data.
Conclusion
Data may be stored globally with the aid of Cosmos DB, making it feasible for databases to be close to users, hence reducing latency. It is also made simpler to index, scale, and achieve high availability thanks to Cosmos DB’s many functionalities.