
It is quite overwhelming to see how fast the world of Big Data Analytics advances. Something or the other is going on each second and it gets really nerve wrecking to stay updated. In this post, I will share some of the latest eye-catching news from the world of Big Data.

There was a time when all-flash storage arrays had a single agenda – critical application to maximise speed, mostly used by large IT concerns. Times have changed now, and these flash storage arrays are all set to penetrate into other parts of IT.
Systems are being reduced in size to suit the needs of a medium-sized enterprise, whereas larger, petabyte-scale flash platforms are getting ready for big data number crunching with high-level performance. The primary reason cited for this is the cost-effectiveness. It is known to all of us that flash media is comparatively cheaper as it packs more data (bits) into the same space; hence, its speed advantage against spinning disks is reachable for most companies. Also, in a large-scale scenario, it increases the efficiency of a data-centre resulting in higher savings.
Pure Storage, a California based enterprise data flash storage company, which has been an enthusiastic promoter of this trend, announces on Monday the FlashBlade, its latest platform which would allow storing petabytes (1 petabyte = 1000 terabytes) of unstructured data like images and posts on the social media. The focus behind developing FlashBlade is to support emerging applications which need fast access to data for real-time decision making. IDC analyst Eric Burgener puts it in a simple way, “This is the kind of technology an athletic-wear company which needs to deliver the product, offers related to the star players in a soccer match that’s still being played.” This allows the company to decide which player’s merchandise they should promote on social media. Pure Storage has said in a statement that the product is still in its beta testing phase and will hopefully be ready for shipping commercially by next year. Car manufacturers who wish to track the airflow simulations are among the very first beta testers.
Another important piece of news comes from the SAP. SAP HANA Vora, released general availability this week. This is for keeping the promise that SAP made to connect conventional enterprise analytics tools to the huge data stored on Hadoop and Spark. Also, the company made another announcement – open source contributions to Apache Spark ecosystem. A lot of business organizations wish to connect Business Intelligence – type tools to big data storage but it is easier said than done. This is the reason why we have witnessed a lot of vendors striving to provide solutions to connect BI – tools to big data, in recent times. The answer up until now has been ELT (extract, load and transform) which is to move a subset of data to another storage location; thus, enabling the Business Intelligence tools to use it. But with the SAP HANA Vora, the business analysts can use OLAP modelling and SQL to analyse data while the data stays in Hadoop.
The following image explains SAP HANA Vora in a simpler way:
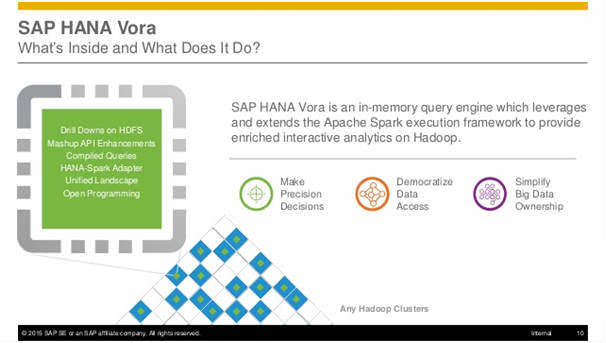
New updates from the Big Data front keep coming in with each passing moment. With so many advancements being made in the field, it is a given that the market is flooded with opportunities. Professionals working in the field of Big Data have a promising career path in the times to come. If you aspire to make a career in the field of Big Data Analytics has become a part of one of the most sought-after professions of our time, then enrol for Cognixia’s Big Data training programs. For further information, you can write to us
